
Image by: izusek, ©2018 Getty Images
Amidst all the hype and hoopla surrounding artificial intelligence (AI), it’s often the simple practicalities that get lost along the way. We spend much of our professional lives talking to organizations about their AI strategy, roadmap, and technology, and the most common question we hear is, “What’s the right approach to AI?”
It’s a good question. Over the next few months, we’ll be sharing some practical, real-world advice on how to get started on your AI project to ensure the best chance for success. A great place to start the discussion is defining what AI is and, just as importantly, what it isn’t. We’ll begin with some common definitions that most experts can agree upon.
In the simplest of terms, AI refers to computers demonstrating human traits of thought and reasoning. While AI is still the ultimate goal, we often use it in more generic terms. In fact, we are several decades away from such general intelligence, but we’re getting pretty darn good at narrowly focused AI. Today, most AI products are technically based on machine learning.
The core idea behind machine learning is deceptively simple: An algorithm learns the rules required to produce the desired output on its own. So, it’s quite different from traditional software programming and applications, as you can see below.
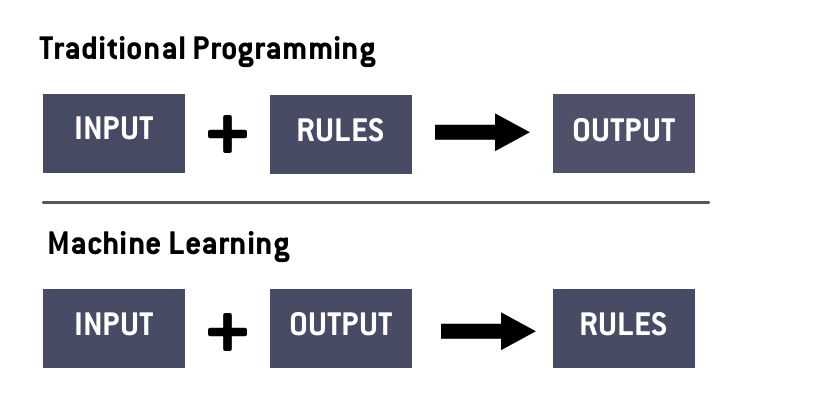
There are three different approaches to machine learning:
- Supervised Learning: This is the most common form of machine learning in use today. With this method, humans initially label all the input data and define the output variable. Then the algorithm is trained to identify the relationship between the input and output variables. Some use cases for supervised learning range from sales prediction to sentiment detection. This approach is best when you know what you're looking for and then use machine learning to define the result.
- Unsupervised Learning: Unlike supervised learning, this approach does not label data. Instead, we rely on machine learning to find the underlying patterns by itself that we would not otherwise know about. For example, this is useful for improving customer segmentation and in recommendation systems.
- Reinforcement Learning: Input data is not labeled with this approach, but a human trainer identifies whether the output produced by the algorithm is correct or incorrect, helping the algorithm to get better over several iterations. A use case for this approach is improving the performance of self-driving cars.
However, a new area that has become quite powerful due to the easy availability to vast amounts of data and computing power is deep learning. This approach is roughly modeled on how some believe the human brain works, utilizing artificial neural networks. In practical terms, this means that there are layers of processing nodes, each interconnecting with another. So, when one node figures out a pattern, it can share that with another node and so on and so forth. Note that deep learning can be supervised or unsupervised.
In almost every area of information management that will be impacted by AI technology, we will most often be looking at relatively basic machine learning methods. Even so, there are many facets to even the simplest form of machine learning that need to be understood in order to gain value from information management.
Alan Pelz-Sharpe is the Founder and Principal Analyst of Deep Analysis, an independent technology research firm focused on next-generation information management. He has over 25 years of experience in the information technology (IT) industry working with a wide variety of end user organizations and vendors. Follow him on Twitter @alan_pelzsharpe.
Kashyap Kompella is the Founder and CEO of RPA2AI, a global industry analyst firm focusing on automation and artificial intelligence. Kashyap has 20 years of experience as a hands-on technologist, industry analyst, and management consultant. Follow him on Twitter @kashyapkompella.







![GettyImages-1211616422-[Converted]](https://cms-static.wehaacdn.com/documentmedia-com/images/GettyImages-1211616422--Converted-.2413.widea.0.jpg)