One of the things I hear over and over is that information capture is a challenge due to the magnitude of information creation. We create information at an astounding rate and store it with the expectation that we will find it when we need it. In some cases, we use programmatic interfaces to capture and ingest this information into an electronic document management system (EDMS), establishing a central location for the user to store, manage and access the information he/she creates. In the paper-based world, we scan documents to digitize and capture them to store and manage in the EDMS. While the technology for this has been and continues to evolve, there is still one aspect that seems to be overlooked time and time again and that is the process by which we capture this information.
Over the years, I have had many conversations with legal experts on how they would approach a case involving captured information, such as documents, whether digitally born or paper-based, and the message has been clear: consistent practice is required. Many of them have told me that the technology would be their last focus. The reason for this is simple: If the technology in place has been installed and maintainer per the vendor specifications, it would be difficult to attack because it would do what it's designed to do, but if the practices around its use are inconsistent, that would open the discussion of inconsistency, allowing challenges of the information management practice as a whole. Capture has been one of the areas often presented in this light. If you do not capture and store your information in a consistent manner that is repeatable and proven, how can you possibly believe that the information you find and present is accurate and complete?
The process of capture
Capture is the first step in the EDMS life cycle, and yet, it's the most commonly overlooked or forgotten process. This is due in large to the number of ways we can capture information. We can use scanners that are centralized or distributed, personal or departmental. We can also use mobile devices to capture paper documents and other physical information relevant to the business, or we can use programmatic interfaces to capture digitally born documents and information directly into the repository in its native format. The question then becomes one about the processes related, not to the technology itself, but to how these technologies are used. Is there a consistent manner in which information is captured, metadata and security controls are applied and the general structure in which they are managed?
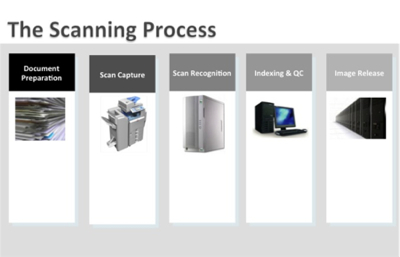 |
Figure 1: The High-Level Scanning Process This a useful reference for those performing the scan function, but it's also a great tool to educate the organization as a whole and to use as a foundation for process mapping and governance guidelines. |
The most common point of reference in the capture of documents is scanning. This, of course, is when we prep the paper documents, scan them, index and store them within a repository of some type. In many cases, there is no documented process for this step in the EDMS life cycle, but it is one that should be documented, consistent and repeatable, as this is also the step where many organizations are allowed to destroy the originals once a digital image is created.
Regardless of the type of device you are using, an overall approach should be implemented and monitored to establish and maintain consistency and repeatability in your scanning process, which also means lower risk and increasing defensibility of your scanning process. The first, and most tedious, step in this process is document prep. In this step, you should be addressing areas that include but are not limited to:
- Logging the documents before scanning
- Removing staples, paper clips and sticky notes
- Smooth wrinkled sheets for better pass through and image quality
- Batch similar sizes, colors, two-sided documents
- Batch documents with similar indexing fields
- Insert separator sheets and attached barcodes, if appropriate
While these are guidelines I am providing, the actual level of detail will be dependent upon your organization, the documents you capture and the capabilities of the technologies you use.
The second step, the act of scanning, is, in fact, where you place the documents into the scanner, multifunction device or other device type you have chosen and, in essence, take the picture. Once this is complete, you may use recognition technology to extract data from the scanned image for purposes of streamlining the third step, indexing. This is also an area where you should have processes in place to ensure quality of the image and accuracy of the extracted data for your indexing operation. Though many of the recognition technologies out there are capable of high levels of accuracy, you should always monitor and make appropriate adjustments to ensure you maintain the highest levels of accuracy.
The final step in the scanning process is release. This is where you store captured information in the repository, using the index information to manage and find it when you need it. Many organizations tie this step to a workflow application, where, at the point of release, a workflow process is triggered to begin a review or action cycle on the newly captured information. Loan applications are one example of this in which an alert may be sent to the appropriate loan officer for review and approval once the application is captured and released.
"Your capture strategy should help define content to be captured and its value, the process in which it will be captured based on its characteristics, like physical versus digitally born, and the manner in which it will be monitored."
Office application capture
Another form of capture is through programmatic interfaces, allowing users to capture digitally born information into the EDMS directly from their word processing, spreadsheet, presentation, report writers and other office productivity applications. Many of the EDMS vendors have taken the initiative to do the integration work, meaning that once the system is all installed and made available to the users, the capture process could be as simple as drag and drop form an email inbox or a menu selection from a toolbar in the spreadsheet application. Again, I present the challenge of consistency and repeatability in that you should have this process configured to capture those metadata elements automatically, when possible, and limit the number of choices for the user, perhaps providing a list of recommended terms from a controlled vocabulary. Not only does this help with consistency and repeatability, it also helps streamline the process.
In my view, a well-planned, documented, implemented and maintained scan process will not only help your organization organize and maintain control over its captured content, it also provides strength and defensible ways to minimize risk related to consistent and repeatable capture practices. Your capture strategy should help define content to be captured and its value, the process in which it will be captured based on its characteristics, like physical versus digitally born, and the manner in which it will be monitored for quality purposes.
Of course, like any other process, once your capture strategy has been defined and documented, you must also train the user community in the importance and adherence to the new way of capturing information. Expect resistance from some and moaning from many, as they will perceive it as being yet another impediment to job performance by adding more levels of work to be done, but rest assured that if you plan, communicate and train everyone properly, the moaning will quickly turn to gratitude, and your risk management team will be thankful that new tools to help maintain regulatory and industry compliance and defensibility has been introduced.
Tweet













