Image by: SIphotography, ©2017 Getty Images
Today, business users want to reach a state of Nirvana where they can find the documents they need effortlessly. Well, I can assure you that you don't have to take meditation classes to achieve such a reality. You heard me right. It's possible to specify what documents you want to search and, no matter the search criteria, format, or origin, they will be presented to you—regardless of where you are and time of day when executing the search.
I'm talking about a unique repository of documents. I mentioned this concept in my last post, and I stand by it, since there are now tools that support it.
As an example, let's say you're an auditor who is hired to research a company's value for a potential acquisition by an outside firm. The company under scrutiny is a global product manufacturer and has offices, partners, and sales channels all over the world. They often present at major exhibitions where their senior leaders deliver keynote speeches.
Initially, you've been given basic reports showing the business, but you want to go deeper. You want to find the source of the data: You want to see contracts with customers, partners, and local landlords; planning documents for new products; pictures and videos taken at exhibitions; topics of keynote presentations given by management; quotes created by local offices for their partners or end customers; partner training documents for each country; etc. So, how can you do this effortlessly?
The Promise of a Unique Repository
The basic idea is that once a document becomes a computer file, it can be stored and searched via metadata assigned to those files or even text associated with them. This way, you simply search the unique repository for whatever criteria you need, and the results will list all the documents satisfying that criteria—whatever their format or origin. Nice, isn't it? Obviously, documents need to follow a certain process, so it's only natural to configure those flows.Of course, there are a couple of catches, and one of them is the configuration of such a system. For example, you will need to address metadata fields, such as type of document, date of document, regional office, subject, or whatever else is necessary to perform a search with real and valid results. The other catch has to do with integration. If we only have a unique repository, that repository must integrate with all the other software applications already being used.
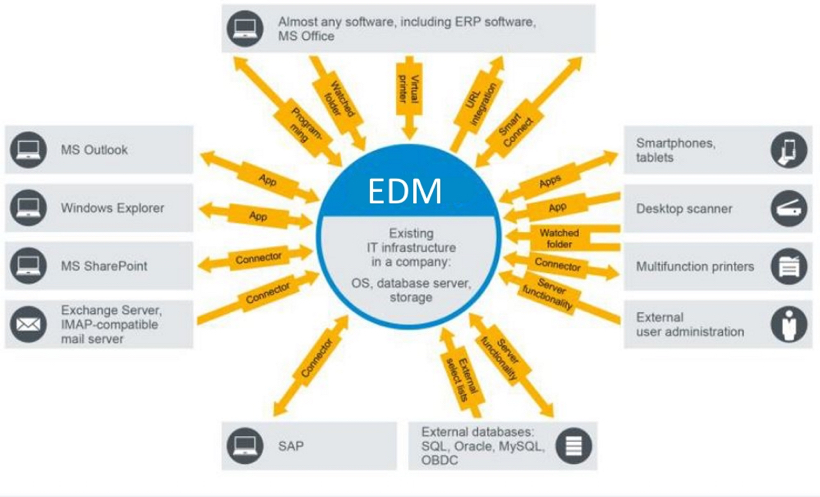
Having said this, I call your attention to a small detail mentioned earlier about that auditor looking for topics of keynote presentations given by management. In order to achieve this, you will need a solution that analyzes the video and its audio track to identify the topics mentioned in that video. In this case, there technically wouldn't be a single physical repository but an infrastructure that a user views as one.
One thing is immutable, however: If your documents are spread among N different locations, you will need resources to search those N places—instead of only one.
Joao Penha-Lopes specializes in document management since 1998. He holds two postgraduate degrees in document management from the University Lusofona (Lisbon) and a PhD from Universidad de Alcala de Henares (Madrid) in 2013, with a thesis studying the economic benefits of electronic document management (EDM). He is an ARMA collaborator for publications and professionally acts as an advisor on critical information flows mostly for private corporations. Follow him on Twitter @JoaoPL1000.